OWASP Top Ten
The OWASP Top 10 is a standard awareness document for developers and web application security. It represents a broad consensus about the most critical security risks to web applications.
Globally recognized by developers as the first step towards more secure coding.
Companies should adopt this document and start the process of ensuring that their web applications minimize these risks. Using the OWASP Top 10 is perhaps the most effective first step towards changing the software development culture within your organization into one that produces more secure code.
Top 10 Web Application Security Risks
There are three new categories, four categories with naming and scoping changes, and some consolidation in the Top 10 for 2021.
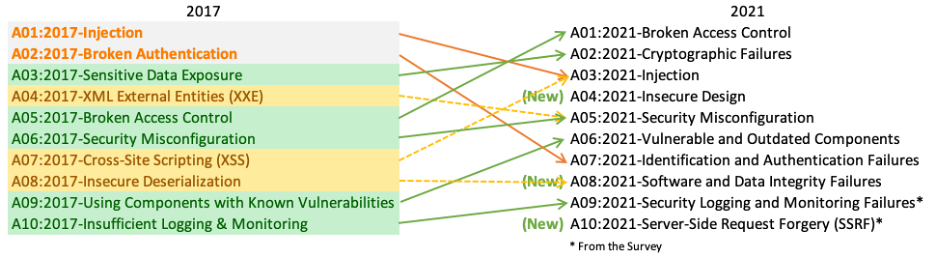
- A01:2021-Broken Access Control moves up from the fifth position; 94% of applications were tested for some form of broken access control. The 34 Common Weakness Enumerations (CWEs) mapped to Broken Access Control had more occurrences in applications than any other category.
- A02:2021-Cryptographic Failures shifts up one position to #2, previously known as Sensitive Data Exposure, which was broad symptom rather than a root cause. The renewed focus here is on failures related to cryptography which often leads to sensitive data exposure or system compromise.
- A03:2021-Injection slides down to the third position. 94% of the applications were tested for some form of injection, and the 33 CWEs mapped into this category have the second most occurrences in applications. Cross-site Scripting is now part of this category in this edition.
- A04:2021-Insecure Design is a new category for 2021, with a focus on risks related to design flaws. If we genuinely want to “move left” as an industry, it calls for more use of threat modeling, secure design patterns and principles, and reference architectures.
- A05:2021-Security Misconfiguration moves up from #6 in the previous edition; 90% of applications were tested for some form of misconfiguration. With more shifts into highly configurable software, it’s not surprising to see this category move up. The former category for XML External Entities (XXE) is now part of this category.
- A06:2021-Vulnerable and Outdated Components was previously titled Using Components with Known Vulnerabilities and is #2 in the Top 10 community survey, but also had enough data to make the Top 10 via data analysis. This category moves up from #9 in 2017 and is a known issue that we struggle to test and assess risk. It is the only category not to have any Common Vulnerability and Exposures (CVEs) mapped to the included CWEs, so a default exploit and impact weights of 5.0 are factored into their scores.
- A07:2021-Identification and Authentication Failures was previously Broken Authentication and is sliding down from the second position, and now includes CWEs that are more related to identification failures. This category is still an integral part of the Top 10, but the increased availability of standardized frameworks seems to be helping.
- A08:2021-Software and Data Integrity Failures is a new category for 2021, focusing on making assumptions related to software updates, critical data, and CI/CD pipelines without verifying integrity. One of the highest weighted impacts from Common Vulnerability and Exposures/Common Vulnerability Scoring System (CVE/CVSS) data mapped to the 10 CWEs in this category. Insecure Deserialization from 2017 is now a part of this larger category.
- A09:2021-Security Logging and Monitoring Failures was previously Insufficient Logging & Monitoring and is added from the industry survey (#3), moving up from #10 previously. This category is expanded to include more types of failures, is challenging to test for, and isn’t well represented in the CVE/CVSS data. However, failures in this category can directly impact visibility, incident alerting, and forensics.
- A10:2021-Server-Side Request Forgery is added from the Top 10 community survey (#1). The data shows a relatively low incidence rate with above average testing coverage, along with above-average ratings for Exploit and Impact potential. This category represents the scenario where the security community members are telling us this is important, even though it’s not illustrated in the data at this time.
Translation Efforts
Efforts have been made in numerous languages to translate the OWASP Top 10 - 2021. If you are interested in helping, please contact the members of the team for the language you are interested in contributing to, or if you don’t see your language listed (neither here nor at github), please email [email protected] to let us know that you want to help and we’ll form a volunteer group for your language. We have compiled this readme with some hints to help you with your translation.
Top10:2021 Completed Translations:
- ar - العربية
- es - Español
- fr - Français
- id - Indonesian
- it - Italiano
- ja - 日本語]
- pt_BR - Português (Brasil)
- zh_CN - 简体中文
- zh_TW - 繁體中文
Historic:
Top10:2017 Completed Translations:
- Chinese: OWASP Top 10-2017 - 中文版(PDF)
- 项目组长:王颉([email protected])
- 翻译人员:陈亮、王厚奎、王颉、王文君、王晓飞、吴楠、徐瑞祝、夏天泽、杨璐、张剑钟、赵学文(排名不分先后,按姓氏拼音排列)
- 审查人员:Rip、包悦忠、李旭勤、杨天识、张家银(排名不分先后,按姓氏拼音排列)
- 汇编人员:赵学文
- French: OWASP Top 10 2017 in French (Git/Markdown)
- German: OWASP Top 10 2017 in German V1.0 (Pdf) (web pages)
compiled by Christian Dresen, Alexios Fakos, Louisa Frick, Torsten Gigler, Tobias Glemser, Dr. Frank Gut, Dr. Ingo Hanke, Dr. Thomas Herzog, Dr. Markus Koegel, Sebastian Klipper, Jens Liebau, Ralf Reinhardt, Martin Riedel, Michael Schaefer - Hebrew: OWASP Top 10-2017 - Hebrew (PDF) (PPTX)
translated by Eyal Estrin (Twitter: @eyalestrin) and Omer Levi Hevroni (Twitter: @omerlh). - Japanese: OWASP Top 10-2017 - 日本語版 (PDF)
translated and reviewed by Akitsugu ITO, Albert Hsieh, Chie TAZAWA, Hideko IGARASHI, Hiroshi TOKUMARU, Naoto KATSUMI, Riotaro OKADA, Robert DRACEA, Satoru TAKAHASHI, Sen UENO, Shoichi NAKATA, Takanori NAKANOWATARI ,Takanori ANDO, Tomohiro SANAE. - Korean: OWASP Top 10-2017 - 한글 (PDF) (PPTX)
번역 프로젝트 관리 및 감수 : 박형근(Hyungkeun Park) / 감수(ㄱㄴㄷ순) : 강용석(YongSeok Kang), 박창렴(Park Changryum), 조민재(Johnny Cho) / 편집 및 감수 : 신상원(Shin Sangwon) / 번역(ㄱㄴㄷ순) : 김영하(Youngha Kim), 박상영(Sangyoung Park), 이민욱(MinWook Lee), 정초아(JUNG CHOAH), 조광렬(CHO KWANG YULL), 최한동(Handong Choi) - Portuguese: OWASP Top 10 2017 - Portuguese (PDF) (ODP)
translated by Anabela Nogueira, Carlos Serrão, Guillaume Lopes, João Pinto, João Samouco, Kembolle A. Oliveira, Paulo A. Silva, Ricardo Mourato, Rui Silva, Sérgio Domingues, Tiago Reis, Vítor Magano. - Russian: OWASP Top 10-2017 - на русском языке (PDF)
translated and reviewed by JZDLin (@JZDLin), Oleksii Skachkov (@hamster4n), Ivan Kochurkin (@KvanTTT) and Taras Ivashchenko - Spanish: OWASP Top 10-2017 - Español (PDF)
- Gerardo Canedo([email protected] - [Twitter: @GerardoMCanedo])
- Cristian Borghello([email protected] - [Twitter: @seguinfo])
Top10:2017 Release Candidate Translation Teams:
- Azerbaijanian: Rashad Aliyev ([email protected])
- Chinese RC2:Rip、包悦忠、李旭勤、王颉、王厚奎、吴楠、徐瑞祝、夏天泽、张家银、张剑钟、赵学文(排名不分先后,按姓氏拼音排列) OWASP Top10 2017 RC2 - Chinese PDF
- French: Ludovic Petit: [email protected], Sébastien Gioria: [email protected].
- Others to be listed.
Top10:2013 Completed Translations:
- Arabic: OWASP Top 10 2013 - Arabic PDF
Translated by: Mohannad Shahat: [email protected], Fahad: @SecurityArk, Abdulellah Alsaheel: [email protected], Khalifa Alshamsi: [email protected] and Sabri(KING SABRI): [email protected], Mohammed Aldossary: [email protected] - Chinese 2013:中文版2013 OWASP Top 10 2013 - Chinese (PDF).
项目组长: Rip、王颉, 参与人员: 陈亮、 顾庆林、 胡晓斌、 李建蒙、 王文君、 杨天识、 张在峰 - Czech 2013: OWASP Top 10 2013 - Czech (PDF) OWASP Top 10 2013 - Czech (PPTX)
CSIRT.CZ - CZ.NIC, z.s.p.o. (.cz domain registry): Petr Zavodsky: [email protected], Vaclav Klimes, Zuzana Duracinska, Michal Prokop, Edvard Rejthar, Pavel Basta - French 2013: OWASP Top 10 2013 - French PDF
Ludovic Petit: [email protected], Sébastien Gioria: [email protected], Erwan Abgrall: [email protected], Benjamin Avet: [email protected], Jocelyn Aubert: [email protected], Damien Azambour: [email protected], Aline Barthelemy: [email protected], Moulay Abdsamad Belghiti: [email protected], Gregory Blanc: [email protected], Clément Capel: [email protected], Etienne Capgras: [email protected], Julien Cayssol: [email protected], Antonio Fontes: [email protected], Ely de Travieso: [email protected], Nicolas Grégoire: [email protected], Valérie Lasserre: [email protected], Antoine Laureau: [email protected], Guillaume Lopes: [email protected], Gilles Morain: [email protected], Christophe Pekar: [email protected], Olivier Perret: [email protected], Michel Prunet: [email protected], Olivier Revollat: [email protected], Aymeric Tabourin: [email protected] - German 2013: OWASP Top 10 2013 - German PDF
[email protected] which is Frank Dölitzscher, Torsten Gigler, Tobias Glemser, Dr. Ingo Hanke, Thomas Herzog, Kai Jendrian, Ralf Reinhardt, Michael Schäfer - Hebrew 2013: OWASP Top 10 2013 - Hebrew PDF
Translated by: Or Katz, Eyal Estrin, Oran Yitzhak, Dan Peled, Shay Sivan. - Italian 2013: OWASP Top 10 2013 - Italian PDF
Translated by: Michele Saporito: [email protected], Paolo Perego: [email protected], Matteo Meucci: [email protected], Sara Gallo: [email protected], Alessandro Guido: [email protected], Mirko Guido Spezie: [email protected], Giuseppe Di Cesare: [email protected], Paco Schiaffella: [email protected], Gianluca Grasso: [email protected], Alessio D’Ospina: [email protected], Loredana Mancini: [email protected], Alessio Petracca: [email protected], Giuseppe Trotta: [email protected], Simone Onofri: [email protected], Francesco Cossu: [email protected], Marco Lancini: [email protected], Stefano Zanero: [email protected], Giovanni Schmid: [email protected], Igor Falcomata’: [email protected] - Japanese 2013: OWASP Top 10 2013 - Japanese PDF
Translated by: Chia-Lung Hsieh: ryusuke.tw(at)gmail.com, Reviewed by: Hiroshi Tokumaru, Takanori Nakanowatari - Korean 2013: OWASP Top 10 2013 - Korean PDF (이름가나다순)
김병효:[email protected], 김지원:[email protected], 김효근:[email protected], 박정훈:[email protected], 성영모:[email protected], 성윤기:[email protected], 송보영:[email protected], 송창기:[email protected], 유정호:[email protected], 장상민:[email protected], 전영재:[email protected], 정가람:[email protected], 정홍순:[email protected], 조민재:[email protected],허성무:[email protected] - Brazilian Portuguese 2013: OWASP Top 10 2013 - Brazilian Portuguese PDF
Translated by: Carlos Serrão, Marcio Machry, Ícaro Evangelista de Torres, Carlo Marcelo Revoredo da Silva, Luiz Vieira, Suely Ramalho de Mello, Jorge Olímpia, Daniel Quintão, Mauro Risonho de Paula Assumpção, Marcelo Lopes, Caio Dias, Rodrigo Gularte - Spanish 2013: OWASP Top 10 2013 - Spanish PDF
Gerardo Canedo: [email protected], Jorge Correa: [email protected], Fabien Spychiger: [email protected], Alberto Hill: [email protected], Johnatan Stanley: [email protected], Maximiliano Alonzo: [email protected], Mateo Martinez: [email protected], David Montero: [email protected], Rodrigo Martinez: [email protected], Guillermo Skrilec: [email protected], Felipe Zipitria: [email protected], Fabien Spychiger: [email protected], Rafael Gil: [email protected], Christian Lopez: [email protected], jonathan fernandez [email protected], Paola Rodriguez: [email protected], Hector Aguirre: [email protected], Roger Carhuatocto: [email protected], Juan Carlos Calderon: [email protected], Marc Rivero López: [email protected], Carlos Allendes: [email protected], [email protected]: [email protected], Manuel Ramírez: [email protected], Marco Miranda: [email protected], Mauricio D. Papaleo Mayada: [email protected], Felipe Sanchez: [email protected], Juan Manuel Bahamonde: [email protected], Adrià Massanet: [email protected], Jorge Correa: [email protected], Ramiro Pulgar: [email protected], German Alonso Suárez Guerrero: [email protected], Jose A. Guasch: [email protected], Edgar Salazar: [email protected] - Ukrainian 2013: OWASP Top 10 2013 - Ukrainian PDF
Kateryna Ovechenko, Yuriy Fedko, Gleb Paharenko, Yevgeniya Maskayeva, Sergiy Shabashkevich, Bohdan Serednytsky
2010 Completed Translations:
- Korean 2010: OWASP Top 10 2010 - Korean PDF
Hyungkeun Park, ([email protected]) - Spanish 2010: OWASP Top 10 2010 - Spanish PDF
Daniel Cabezas Molina, Edgar Sanchez, Juan Carlos Calderon, Jose Antonio Guasch, Paulo Coronado, Rodrigo Marcos, Vicente Aguilera - French 2010: OWASP Top 10 2010 - French PDF
[email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] - German 2010: OWASP Top 10 2010 - German PDF
[email protected] which is Frank Dölitzscher, Tobias Glemser, Dr. Ingo Hanke, Kai Jendrian, Ralf Reinhardt, Michael Schäfer - Indonesian 2010: OWASP Top 10 2010 - Indonesian PDF
Tedi Heriyanto (coordinator), Lathifah Arief, Tri A Sundara, Zaki Akhmad - Italian 2010: OWASP Top 10 2010 - Italian PDF
Simone Onofri, Paolo Perego, Massimo Biagiotti, Edoardo Viscosi, Salvatore Fiorillo, Roberto Battistoni, Loredana Mancini, Michele Nesta, Paco Schiaffella, Lucilla Mancini, Gerardo Di Giacomo, Valentino Squilloni - Japanese 2010: OWASP Top 10 2010 - Japanese PDF
[email protected], Dr. Masayuki Hisada, Yoshimasa Kawamoto, Ryusuke Sakamoto, Keisuke Seki, Shin Umemoto, Takashi Arima - Chinese 2010: OWASP Top 10 2010 - Chinese PDF
感谢以下为中文版本做出贡献的翻译人员和审核人员: Rip Torn, 钟卫林, 高雯, 王颉, 于振东 - Vietnamese 2010: OWASP Top 10 2010 - Vietnamese PDF
Translation lead by Cecil Su - Translation Team: Dang Hoang Vu, Nguyen Ba Tien, Nguyen Tang Hung, Luong Dieu Phuong, Huynh Thien Tam - Hebrew 2010: OWASP Top 10 Hebrew Project – OWASP Top 10 2010 - Hebrew PDF.
Lead by Or Katz, see translation page for list of contributors.
2021 Project Sponsors
The OWASP Top 10:2021 is sponsored by Secure Code Warrior.

2017 Project Sponsors
The OWASP Top 10 - 2017 project was sponsored by Autodesk, and supported by the OWASP NoVA Chapter.

2003-2013 Project Sponsors
Thanks to Aspect Security for sponsoring earlier versions.
OWASP Top 10 2021 Data Analysis Plan
Goals
To collect the most comprehensive dataset related to identified application vulnerabilities to-date to enable analysis for the Top 10 and other future research as well. This data should come from a variety of sources; security vendors and consultancies, bug bounties, along with company/organizational contributions. Data will be normalized to allow for level comparison between Human assisted Tooling and Tooling assisted Humans.
Analysis Infrastructure
Plan to leverage the OWASP Azure Cloud Infrastructure to collect, analyze, and store the data contributed.
Contributions
We plan to support both known and pseudo-anonymous contributions. The preference is for contributions to be known; this immensely helps with the validation/quality/confidence of the data submitted. If the submitter prefers to have their data stored anonymously and even go as far as submitting the data anonymously, then it will have to be classified as “unverified” vs. “verified”.
Verified Data Contribution
Scenario 1: The submitter is known and has agreed to be identified as a contributing party.
Scenario 2: The submitter is known but would rather not be publicly identified.
Scenario 3: The submitter is known but does not want it recorded in the dataset.
Unverified Data Contribution
Scenario 4: The submitter is anonymous. (Should we support?)
The analysis of the data will be conducted with a careful distinction when the unverified data is part of the dataset that was analyzed.
Contribution Process
There are a few ways that data can be contributed:
- Email a CSV/Excel file with the dataset(s) to [email protected]
- Upload a CSV/Excel file to a “contribution folder” (coming soon)
Template examples can be found in GitHub: https://github.com/OWASP/Top10/tree/master/2021/Data
Contribution Period
We plan to accept contributions to the new Top 10 from May to Nov 30, 2020 for data dating from 2017 to current.
Data Structure
The following data elements are required or optional.
The more information provided the more accurate our analysis can be.
At a bare minimum, we need the time period, total number of applications tested in the dataset, and the list of CWEs and counts of how many applications contained that CWE.
If at all possible, please provide the additional metadata, because that will greatly help us gain more insights into the current state of testing and vulnerabilities.
Metadata
- Contributor Name (org or anon)
- Contributor Contact Email
- Time period (2019, 2018, 2017)
- Number of applications tested
- Type of testing (TaH, HaT, Tools)
- Primary Language (code)
- Geographic Region (Global, North America, EU, Asia, other)
- Primary Industry (Multiple, Financial, Industrial, Software, ??)
- Whether or not data contains retests or the same applications multiple times (T/F)
CWE Data
- A list of CWEs w/ count of applications found to contain that CWE
If at all possible, please provide core CWEs in the data, not CWE categories.
This will help with the analysis, any normalization/aggregation done as a part of this analysis will be well documented.
Note:
If a contributor has two types of datasets, one from HaT and one from TaH sources, then it is recommended to submit them as two separate datasets.
HaT = Human assisted Tools (higher volume/frequency, primarily from tooling)
TaH = Tool assisted Human (lower volume/frequency, primarily from human testing)
Survey
Similarly to the Top Ten 2017, we plan to conduct a survey to identify up to two categories of the Top Ten that the community believes are important, but may not be reflected in the data yet. We plan to conduct the survey in May or June 2020, and will be utilizing Google forms in a similar manner as last time. The CWEs on the survey will come from current trending findings, CWEs that are outside the Top Ten in data, and other potential sources.
Process
At a high level, we plan to perform a level of data normalization; however, we will keep a version of the raw data contributed for future analysis. We will analyze the CWE distribution of the datasets and potentially reclassify some CWEs to consolidate them into larger buckets. We will carefully document all normalization actions taken so it is clear what has been done.
We plan to calculate likelihood following the model we developed in 2017 to determine incidence rate instead of frequency to rate how likely a given app may contain at least one instance of a CWE. This means we aren’t looking for the frequency rate (number of findings) in an app, rather, we are looking for the number of applications that had one or more instances of a CWE. We can calculate the incidence rate based on the total number of applications tested in the dataset compared to how many applications each CWE was found in.
In addition, we will be developing base CWSS scores for the top 20-30 CWEs and include potential impact into the Top 10 weighting.
Also, would like to explore additional insights that could be gleaned from the contributed dataset to see what else can be learned that could be of use to the security and development communities.