OWASP Benchmark
OWASP Benchmark Project
The OWASP Benchmark Project contains test suites in different languages along with scoring tools designed to evaluate the accuracy, coverage, and speed of automated software vulnerability detection tools for different programming languages. Without the ability to measure these tools, it is difficult to understand their strengths and weaknesses, and compare them to each other.
OWASP Benchmark provides multiple fully runnable open source web application that contains thousands of exploitable test cases, each mapped to specific CWEs, which can be analyzed by any type of Application Security Testing (AST) tool, including SAST, DAST (like ZAP), and IAST tools. The intent is that all the vulnerabilities deliberately included in and scored by the Benchmark are actually exploitable so its a fair test for any kind of application vulnerability detection tool. The Benchmark also includes dozens of scorecard generators for numerous open source and commercial AST tools, and the set of supported tools is growing all the time.
OWASP Benchmark for Java
The initial version 1.0 of the OWASP Benchmark for Java was released in 2015. Version 1.2, which added a full web UI and other improvments was released in 2016 and has been maintained since that without substantial changes to the test cases.
OWASP Benchmark for Python
The Benchmark Project has just released an initial v0.1 version of a new OWASP Benchmark for Python, which we plan to work on refining and improving to get a v1.0 release out in early 2026.
Related Projects
Summary
Version 1.2 and forward of the OWASP Benchmark for Java is a fully executable web application, which means it is scannable by any kind of vulnerability detection tool. v1.2 has been limited to slightly less than 3,000 test cases, to make it easier for DAST tools to scan it (so it doesn’t take so long and they don’t run out of memory, or blow up the size of their database). The 1.2 release covers the same vulnerability areas that 1.1 covers. The bulk of the work was turning each test case into something that actually runs correctly and is fully exploitable, and then generating a UI on top that works in order to turn the test cases into a real running application.
The test case areas and quantities for the OWASP Benchmark for Java releases are:
| Vulnerability Area | # of Tests in v1.1 | # of Tests in v1.2 | CWE Number |
|---|---|---|---|
| Command Injection | 2708 | 251 | 78 |
| Weak Cryptography | 1440 | 246 | 327 |
| Weak Hashing | 1421 | 236 | 328 |
| LDAP Injection | 736 | 59 | 90 |
| Path Traversal | 2630 | 268 | 22 |
| Secure Cookie Flag | 416 | 67 | 614 |
| SQL Injection | 3529 | 504 | 89 |
| Trust Boundary Violation | 725 | 126 | 501 |
| Weak Randomness | 3640 | 493 | 330 |
| XPATH Injection | 347 | 35 | 643 |
| XSS (Cross-Site Scripting) | 3449 | 455 | 79 |
| Total Test Cases | 21,041 | 2,740 |
Each Benchmark version comes with a spreadsheet that lists every test case, the vulnerability category, the CWE number, and the expected result (true finding/false positive). Look for the file: expectedresults-VERSION#.csv in the project root directory.
Every test case is:
- an HTTP Servlet
- a true vulnerability or a false positive for a single CWE
OWASP Benchmark for Java Release History
- Version 1.0 of the Benchmark for Java was released April 15, 2015 and had 20,983 test cases.
- Version 1.1 of the Benchmark for Java was released May 23, 2015. The 1.1 release improved on the previous version by making sure that there are both true positives and false positives in every vulnerability area.
- Version 1.2 was first released on June 5, 2016 (The 1.2beta was August 15, 2015). There have been constant tweaks to the v1.2 release since then.
Potential future enhancements:
- All vulnerability types in the OWASP Top 10
- Does the tool find flaws in libraries?
- Does the tool find flaws spanning custom code and libraries?
- Does tool handle web services? REST, XML, GWT, etc?
- Does tool work with different app servers? Java platforms?
- JSPs
- More popular frameworks
- Inversion of control
- Reflection
- Class loading
- Annotations
- Popular UI technologies (e.g., JavaScript frameworks)
- Entirely new languages (C#, Python, etc.)
Example Test Case
Each test case is a simple Java EE servlet. BenchmarkTest00001 in version 1.0 of the Benchmark was an LDAP Injection test with the following metadata in the accompanying BenchmarkTest00001.xml file:
xml
<test-metadata>
<category>ldapi</category>
<test-number>00001</test-number>
<vulnerability>true</vulnerability>
<cwe>90</cwe>
</test-metadata>
BenchmarkTest00001.java in the OWASP Benchmark for Java 1.0 simply reads in all the cookie values, looks for a cookie named “foo”, and uses the value of this cookie when performing an LDAP query. Here’s the code for BenchmarkTest00001.java:
java
package org.owasp.benchmark.testcode;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/BenchmarkTest00001")
public class BenchmarkTest00001 extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// some code
javax.servlet.http.Cookie[] cookies = request.getCookies();
String param = null;
boolean foundit = false;
if (cookies != null) {
for (javax.servlet.http.Cookie cookie : cookies) {
if (cookie.getName().equals("foo")) {
param = cookie.getValue();
foundit = true;
}
}
if (!foundit) {
// no cookie found in collection
param = "";
}
} else {
// no cookies
param = "";
}
try {
javax.naming.directory.DirContext dc = org.owasp.benchmark.helpers.Utils.getDirContext();
Object[] filterArgs = {"a","b"};
dc.search("name", param, filterArgs, new javax.naming.directory.SearchControls());
} catch (javax.naming.NamingException e) {
throw new ServletException(e);
}
}
}
Summary
Version 0.1 of the OWASP Benchmark for Python is a fully executable web application, which means it is scannable by any kind of vulnerability detection tool. v0.1 is a preliminary release that we plan to refine and improve over the next few months to get to a full v1.0 release that is similar to the level of completeness of the OWASP Benchmark for Java v1.2.
The test case areas and quantities for the initial OWASP Benchmark for Python v0.1 are:
| Vulnerability Area | # of Tests in v0.1 | CWE Number |
|---|---|---|
| Code Injection | 53 | 94 |
| Command Injection | 20 | 78 |
| Deserialization of Untrusted Data | 54 | 502 |
| LDAP Injection | 29 | 90 |
| Path Traversal | 168 | 22 |
| Secure Cookie Flag | 39 | 614 |
| SQL Injection | 16 | 89 |
| Trust Boundary Violation | 37 | 501 |
| Unchecked Redirects | 34 | 601 |
| Weak Hashing | 151 | 328 |
| Weak Randomness | 326 | 330 |
| XPath Injection | 186 | 643 |
| XSS (Cross-Site Scripting) | 89 | 79 |
| XXE (XML eXternal Entity Injection) | 28 | 611 |
| Total Test Cases | 1,230 |
Future Work
Other CWEs we might add:
- Weak Cryptography - CWE 327
- Regex DOS - CWE 1333
We will also likely work on trying to balance the number of true positives and false positives per test case category to be more even.
Test Cases
Each Benchmark version comes with an expected results spreadsheet that lists every test case, the vulnerability category, the CWE number, and the expected result (true finding/false positive). Look for the file: expectedresults-VERSION#.csv in the project root directory.
Every test case is:
- a single web page and web endpoint
- a true vulnerability or a false positive for a single CWE
The structure and organization of the new Benchmark for Python is very similar to the OWASP Benchmark for Java v1.2.
Requests
Please provide us with feedback on any suggested fixes/improvements/bugs or tools you’d like to us to add scanning support for. As well as CWEs or Popular Python frameworks we should add test cases for.
Acknowledgements
The OWASP Benchmark project would like to thank the contributions of AppSecAI (https://www.appsecai.io) and their team members Theo Cartsonis and Jessica Salawu for doing the bulk of the development work to produce this first release of the Benchmark for Python test suite.
Introduction
One of the unique things about OWASP Benchmark is that it is very easy to score a tool’s security analysis results against it. Each test case in Benchmark has a single intentional CWE that is either a True or False Positive. These are documented in the expectedresults-1.2.csv file. The project includes automated scorecard generators for dozens of security tools that can automatically score a tool’s results against Benchmark. The following describes the Benchmark scoring scheme, reporting format, and how to actually generate Benchmark scores for tools.
Benchmark Project Scoring Philosophy
Security tools (SAST, DAST, and IAST) are amazing when they find a complex vulnerability in your code. But with widespread misunderstanding of the specific vulnerabilities automated tools cover, end users are often left with a false sense of security.
We are on a quest to measure just how good these tools are at discovering and properly diagnosing security problems in applications. We rely on the long history of military and medical evaluation of detection technology as a foundation for our research. Therefore, the test suite tests both real and fake vulnerabilities.
There are four possible test outcomes in the Benchmark:
- Tool correctly identifies a real vulnerability (True Positive - TP)
- Tool fails to identify a real vulnerability (False Negative - FN)
- Tool correctly ignores a false alarm (True Negative - TN)
- Tool fails to ignore a false alarm (False Positive - FP)
We can learn a lot about a tool from these four metrics. Consider a tool that simply flags every line of code as vulnerable. This tool will perfectly identify all vulnerabilities! But it will also have 100% false positives and thus adds no value. Similarly, consider a tool that reports absolutely nothing. This tool will have zero false positives, but will also identify zero real vulnerabilities and is also worthless. You can even imagine a tool that flips a coin to decide whether to report whether each test case contains a vulnerability. The result would be 50% true positives and 50% false positives. We need a way to distinguish valuable security tools from these trivial ones.
If you imagine the line that connects all these points, from 0,0 to 100,100 establishes a line that roughly translates to “random guessing.” The ultimate measure of a security tool is how much better it can do than this line. The diagram below shows how we will evaluate security tools against the Benchmark.
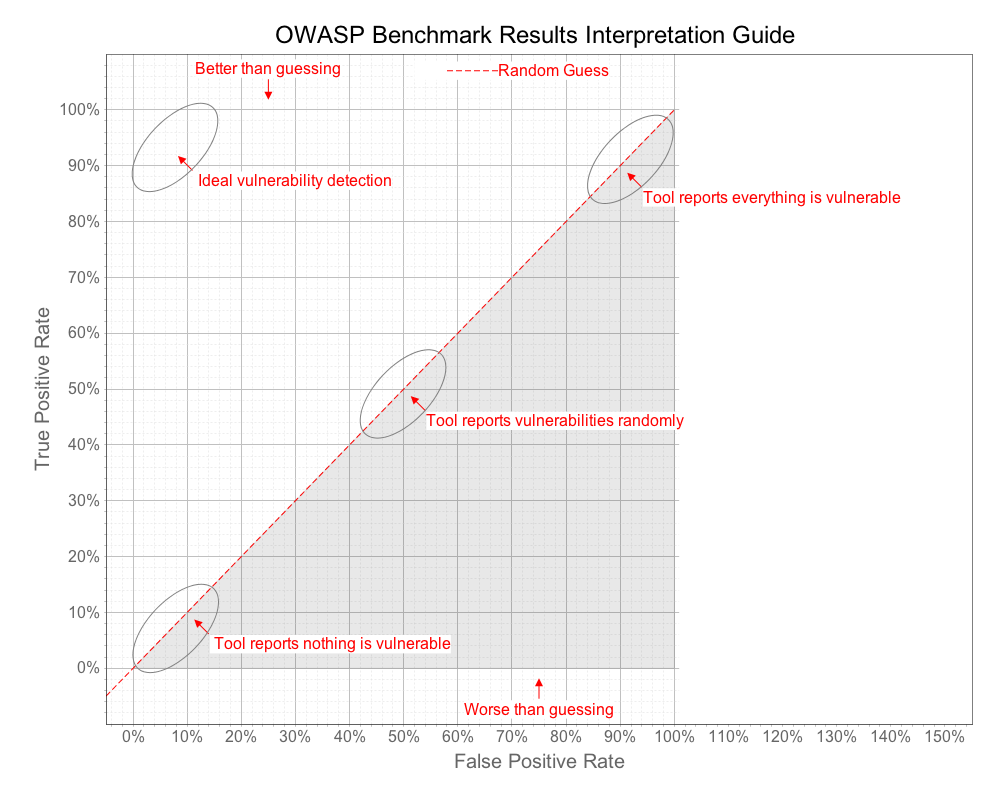 A point plotted on this chart provides a visual indication of how well a tool did considering both the True Positives the tool reported, as well as the False Positives it reported. We also want to compute an individual score for that point in the range 0 - 100, which we call the Benchmark Accuracy Score.
A point plotted on this chart provides a visual indication of how well a tool did considering both the True Positives the tool reported, as well as the False Positives it reported. We also want to compute an individual score for that point in the range 0 - 100, which we call the Benchmark Accuracy Score.
The Benchmark Accuracy Score is essentially a Youden Index, which is a standard way of summarizing the accuracy of a set of tests. Youden’s index is one of the oldest measures for diagnostic accuracy. It is also a global measure of a test performance, used for the evaluation of overall discriminative power of a diagnostic procedure and for comparison of this test with other tests. Youden’s index is calculated by deducting 1 from the sum of a test’s sensitivity and specificity expressed not as percentage but as a part of a whole number: (sensitivity + specificity) - 1. For a test with poor diagnostic accuracy, Youden’s index equals 0, and in a perfect test Youden’s index equals 1.
code()
So for example, if a tool has a True Positive Rate (TPR) of .98 (i.e., 98%)
and False Positive Rate (FPR) of .05 (i.e., 5%)
Sensitivity = TPR (.98)
Specificity = 1-FPR (.95)
So the Youden Index is (.98+.95) - 1 = .93
And this would equate to a Benchmark score of 93 (since we normalize this to the range 0 - 100)
On the graph, the Benchmark Score is the length of the line from the point down to the diagonal “guessing” line. Note that a Benchmark score can actually be negative if the point is below the line. This is caused when the False Positive Rate is actually higher than the True Positive Rate.
Generating Benchmark Scores
Anyone can use this Benchmark to evaluate vulnerability detection tools. The basic steps are:
- Download the Benchmark from GitHub
- Run your tools against the Benchmark
- Run the BenchmarkScore tool on the reports from your tools That’s it!
Full details on how to do this are at the bottom of the page on the Quick Start tab.
We encourage both vendors, open-source tools, and end users to verify their application security tools against the Benchmark. In order to ensure that the results are fair and useful, we ask that you follow a few simple rules when publishing results. We won’t recognize any results that aren’t easily reproducible:
- A description of the default “out-of-the-box” installation, version numbers, etc.
- Any and all configuration, tailoring, onboarding, etc. performed to make the tool run
- Any and all changes to default security rules, tests, or checks used to achieve the results
- Easily reproducible steps to run the tool
Reporting Format
The Benchmark includes tools to interpret raw tool output, compare it to the expected results, and generate summary charts and graphs. We use the following table format in order to capture all the information generated during the evaluation.
| Security Category | TP | FN | TN | FP | Total | TPR | FPR | Score |
|---|---|---|---|---|---|---|---|---|
| General security category for test cases. | True Positives: Tests with real vulnerabilities that were correctly reported as vulnerable by the tool. | False Negative: Tests with real vulnerabilities that were not correctly reported as vulnerable by the tool. | True Negative: Tests with fake vulnerabilities that were correctly not reported as vulnerable by the tool. | False Positive: Tests with fake vulnerabilities that were incorrectly reported as vulnerable by the tool. | Total test cases for this category. | True Positive Rate: TP / ( TP + FN ) - Also referred to as Recall, as defined at Wikipedia. | False Positive Rate: FP / ( FP + TN ). | Normalized distance from the “guess line” TPR - FPR. |
| Command Injection | … | … | … | … | … | … | … | … |
| Etc. | … | … | … | … | … | … | … | … |
| Total TP | Total FN | Total TN | Total FP | Total TC | Average TPR | Average FPR | Average Score |
Benchmark Validity
To be clear, the Benchmark tests are not exactly like real applications. The tests are derived from coding patterns observed in real applications, but the majority of them are considerably simpler than real applications. That is, most real-world applications will be considerably harder to successfully analyze than the OWASP Benchmark Test Suite. Although the tests are based on real code, it is possible that some tests may have coding patterns that don’t occur frequently in real code.
Remember, we are trying to test the capabilities of the tools and make them explicit, so that users can make informed decisions about what tools to use, how to use them, and what results to expect. This is exactly aligned with the OWASP mission to make application security visible.
What is in the Benchmark for Java?
The Benchmark for Java is a Java Maven project. Its primary component is thousands of test cases (e.g., BenchmarkTest00001.java), each of which is a single Java servlet that contains a single vulnerability (either a true positive or false positive). The vulnerabilities span about a dozen different CWEs currently.
An expectedresults.csv is published with each version of the Benchmark (e.g., expectedresults-1.2.csv) and it specifically lists the expected results for each test case. Here’s what the first two rows in this file looks like for version 1.1 of the Benchmark:
# test name category real vulnerability CWE Benchmark version: 1.1 2015-05-22
BenchmarkTest00001 crypto TRUE 327
This simply means that the first test case is a crypto test case (use of weak cryptographic algorithms), this is a real vulnerability (as opposed to a false positive), and this issue maps to CWE 327. It also indicates this expected results file is for Benchmark version 1.1 (produced May 22, 2015). There is a row in this file for each of the tens of thousands of test cases in the Benchmark. Each time a new version of the Benchmark is published, a new corresponding results file is generated and each test case can be completely different from one version to the next.
The Benchmark for Java also comes with a bunch of different utilities, commands, and prepackaged open source security analysis tools, all of which can be executed through Maven goals, including:
- Open source vulnerability detection tools to be run against the Benchmark
- A scorecard generator, which computes a scorecard for each of the tools you have results files for.
What Can You Do With the Benchmark?
- Compile all the software in the Benchmark project (e.g., mvn compile)
- Run a static vulnerability analysis tool (SAST) against the Benchmark test case code
- Scan a running version of the Benchmark with a dynamic application security testing tool (DAST)
- Instructions on how to run it are provided below
- Generate scorecards for each of the tools you have results for
- See the Tool Support/Results page for the list of tools the Benchmark supports generating scorecards for
Getting Started
Before downloading or using the Benchmark for Java make sure you have the following installed and configured properly:
GIT: https://git-scm.com/ or https://github.com/
Maven: https://maven.apache.org/ (Version: 3.2.3 or newer works.)
Java: https://www.oracle.com/java/technologies/javase-downloads.html (Java 7 or 8) (64-bit)
Getting, Building, and Running the Benchmark for Java
To download and build everything:
$ git clone https://github.com/OWASP-Benchmark/BenchmarkJava
$ cd BenchmarkJava
$ mvn compile (This compiles it)
$ runBenchmark.sh/.bat - This compiles and runs it.
Then navigate to: https://localhost:8443/benchmark/ to go to its home page. It uses a self signed SSL certificate, so you’ll get a security warning when you hit the home page.
Note: We have set the Benchmark for Java app to use up to 6 Gig of RAM, which it may need when it is fully scanned by a DAST scanner. The DAST tool probably also requires 3+ Gig of RAM. As such, we recommend having a 16 Gig machine if you are going to try to run a full DAST scan. And at least 4 or ideally 8 Gig if you are going to play around with the running Benchmark app.
Using a VM instead
We have several preconstructed VMs or instructions on how to build one that you can use instead:
- Docker: A Dockerfile is checked into the project here. This Docker file should automatically produce a Docker VM with the latest Benchmark project files. After you have Docker installed, cd to /VMs then run:
./buildDockerImage.sh --> This builds the Docker Benchmark VM (This will take a WHILE) docker images --> You should see the new benchmark:latest image in the list provided # The Benchmark Docker Image only has to be created once.To run the Benchmark in your Docker VM, just run:
./runDockerImage.sh --> This pulls in any updates to Benchmark since the Image was built, builds everything, and starts a remotely accessible Benchmark web app.If successful, you should see this at the end:
[INFO]_[talledLocalContainer] Tomcat 8.x started on port [8443] [INFO] Press Ctrl-C to stop the container...Then simply navigate to: https://localhost:8443/benchmark from the machine you are running Docker
Or if you want to access from a different machine:
docker-machine ls (in a different terminal) --> To get IP Docker VM is exporting (e.g., tcp://192.168.99.100:2376)
Navigate to: https://192.168.99.100:8443/benchmark in your browser (using the above IP as an example)
- Amazon Web Services (AWS) - Here’s how you set up the Benchmark on an AWS VM:
sudo yum install git
sudo yum install maven
sudo yum install mvn
sudo wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
sudo sed -i s/\$releasever/6/g /etc/yum.repos.d/epel-apache-maven.repo
sudo yum install -y apache-maven
git clone https://github.com/OWASP-Benchmark/BenchmarkJava
cd benchmark
chmod 755 *.sh
./runBenchmark.sh -- to run it locally on the VM.
./runRemoteAccessibleBenchmark.sh -- to run it so it can be accessed outside the VM (on port 8443).
Running Free Static Analysis Tools Against the Benchmark for Java
There are scripts for running each of the free SAST vulnerability detection tools included with the Benchmark against the Benchmark test cases. On Linux, you might have to make them executable (e.g., chmod 755 *.sh) before you can run them.
Generating Test Results for PMD: ./scripts/runPMD.sh (Linux) or .\scripts\runPMD.bat (Windows)
Generating Test Results for FindBugs: ./scripts/runFindBugs.sh (Linux) or .\scripts\runFindBugs.bat (Windows)
Generating Test Results for FindBugs with the FindSecBugs plugin: ./scripts/runFindSecBugs.sh (Linux) or .\scripts\runFindSecBugs.bat (Windows)
In each case, the script will generate a results file and put it in the /results directory. For example: Benchmark_1.2-findbugs-v3.0.1-1026.xml
This results file name is carefully constructed to mean the following: It’s a results file against the OWASP Benchmark for Java version 1.2, FindBugs was the analysis tool, it was version 3.0.1 of FindBugs, and it took 1026 seconds to run the analysis.
NOTE: If you create a results file yourself, by running a commercial tool for example, you can add the version # and the compute time to the filename just like this and the Benchmark Scorecard generator will pick this information up and include it in the generated scorecard. If you don’t, depending on what metadata is included in the tool results, the Scorecard generator might do this automatically anyway.
Generating Scorecards
The scorecard generation application BenchmarkUtils (https://github.com/OWASP-Benchmark/BenchmarkUtils) needs to be cloned and installed with Maven. It parses the output files generated by any of the supported security tools run against the Benchmark and compares them against the expected results, and produces a set of web pages that detail the accuracy and speed of the tools involved. For the list of currently supported tools, check out the: Tools Support/Results tab. If you are using a tool that is not yet supported, simply send us a results file from that tool and we’ll write a parser for that tool and add it to the supported tools list.
The following command will compute a Benchmark scorecard for all the results files in the /results directory. The generated scorecard is put into the /scorecard directory.
createScorecard.sh (Linux) or createScorecard.bat (Windows)
An example of a real scorecard for some open source tools is provided at the top of the Tool Support/Results tab so you can see what one looks like.
We recommend including the Benchmark version number in any results file name, in order to help prevent mismatches between the expected results and the actual results files. A tool will not score well against the wrong expected results.
Customizing Your Scorecard Generation
The createScorecard scripts are very simple. They only have one line. Here’s what the 1.2 version looks like:
org.owasp:benchmarkutils-maven-plugin:create-scorecard
This Maven command simply says to run the BenchmarkScore application. It automatically finds the expected results file in the same folder and uses it to generate the scorecard.
In all cases, the generated scorecard is put in the /scorecard folder.
WARNING: If you generate results for a commercial tool, be careful who you distribute it to. Each tool has its own license defining when any results it produces can be released/made public. It is likely to be against the terms of a commercial tool’s license to publicly release that tool’s score against the OWASP Benchmark. The OWASP Benchmark project takes no responsibility if someone else releases such results. It is for just this reason that the Benchmark project isn’t releasing such results itself.
The results, from several years ago, for 5 free tools, PMD, FindBugs, FindBugs with the FindSecBugs plugin, SonarQube, and ZAP are available here against version 1.2 of the Benchmark for Java: https://github.com/OWASP-Benchmark/BenchmarkJava/blob/master/scorecard/OWASP_Benchmark_Home.html. You’ll have to clone this Git repo and open the file locally. We included multiple versions of FindSecBugs’ and ZAP’s results so you can see the improvements they made finding vulnerabilities in Benchmark.
We have Benchmark for Java results for all the following tools, but haven’t publicly released the results for any commercial tools. However, we included a ‘Commercial Average’ page, which includes a summary of results for 6 commercial SAST tools in 2016 along with anonymous versions of each SAST tool’s scorecard.
The Benchmark Project can score results for the following tools (using BenchmarkUtils):
Free Static Application Security Testing (SAST) Tools (Both Open Source and Commercial):
- Bandit(Python) - .sarif results file
- Bearer(Python) - .json results file
- CodeQL - .sarif results file (Support for both Java and Python Benchmarks)
- Contrast CodeSec - Scan - .json SARIF format results file
- FindBugs - .xml results file
- Note: FindBugs hasn’t been updated since 2015. Use SpotBugs instead (see below)
- Horusec - .json results file
- Insider - .json results file
- PMD (which really has no security rules) - .xml results file
- Precaution - .sarif results file
- Semgrep Code - .sarif results file (.json format supported too)
- e.g., semgrep -f https://semgrep.dev/p/r2c-security-audit . –sarif > results/Benchmark_1.2-Semgrep.sarif
- ShiftLeft Scan - .json results file (found at reports/scan-full-report.json)
- Snyk Code - .sarif results file (note: –json produces the same sarif file)
- e.g., snyk code test –sarif-file-output=results/Benchmark_1.2-Snyk.sarif
- SonarQube Community Edition - .xml results file
- SpotBugs - .xml results file. This is the successor to FindBugs.
- SpotBugs with the FindSecurityBugs plugin - .xml results file
- Visual Code Grepper - Soure Code here - .xml results file
Many free Open Source SAST tools come bundled with each Benchmark version so you can run them yourselves. Simply run script/runTOOLNAME.(sh/bat) and it puts the results into the /results directory automatically. There are scripts for running PMD, FindBugs, SpotBugs, and FindSecBugs on the Benchmark for Java, for example.
Note: For Benchmark for Java, we looked into supporting Checkstyle but it has no security rules, just like PMD. The fb-contrib FindBugs plugin doesn’t have any security rules either. We did test Error Prone, and found that it does report some use of insecure ciphers (CWE-327), but that’s it.
Commercial (non-Free) SAST Tools:
- CAST Application Intelligence Platform (AIP), which is a component of CAST Imaging - .xml results file
- Checkmarx SAST - .xml results file
- Contrast Scan - .json SARIF format results file
- HCL AppScan Source (Standalone and Cloud) - .xml (or legacy .ozasmt) results file
- Julia Analyzer - Acquired by Grammatech. No parser for this new solution yet.
- Kiuwan SAST - .threadfix results file
- Mend SAST - Formerly WhiteSource and before that XANITIZER - .xml results file
- OpenText Fortify - .fpr results file (Java and Python)
- Parasoft Jtest - .xml results file
- Semmle LGTM - .sarif results file
- Qwiet Next Gen SAST (Was ShiftLeft SAST) - .sl results file (Benchmark specific format. Ask vendor how to generate this.)
- SnappyTick Source Edition (SAST) - .xml results file
- SonarQube Developer Edition (or greater) - .xml results file (same format as Free version)
- SourceMeter - .txt results file of ALL results from VulnerabilityHunter
- Black Duck Coverity SAST (On-Demand and stand-alone versions) - .json results file (You can scan Benchmark w/Coverity for free. See: https://scan.coverity.com/)
- Veracode SAST - .xml results file
We are looking for results for other commercial SAST tools. If you have a license for any static analysis tool not already listed above and can run it on Benchmark and send us the results file that would be very helpful.
If you have a license for any commercial SAST tool, you can also run them against the Benchmark. Just put your results files in the /results folder of the project, and then run createScorecards.sh/.bat and it will generate a scorecard in the /scorecard directory for all the tool results you have that are currently supported.
Free Dynamic Application Security Testing (DAST) Tools (Both Open Source and Commercial):
Note: While we support scorecard generators for these Free and Commercial DAST tools, it can be difficult to get a full/clean run against the Benchmark. As such, some of these scorecard generators might need some additional work to properly reflect their results. If you notice any problems, let us know.
- Arachni - .xml results file
- To generate .xml, run: ./bin/arachni_reporter “Your_AFR_Results_Filename.afr” –reporter=xml:outfile=Benchmark1.2-Arachni.xml
- Burp Suite Community Edition - .xml results file * To generate XML results: click on benchmark in site map so you see ALL findings in Issues pane. Then select ALL issues in Issues pane, right-click and select ‘Report selected issues’. Select XML, then next, next, next, and save to file. To reduce size of results file, you can eliminate all the details, and not include requests/responses, which reduces the file size by 2/3rds.
- ZAP - .json or .xml results file. To generate a complete ZAP results file so you can generate a valid scorecard, make sure you:
- Tools > Options > Alerts - And set the Max alert instances to like 500.
- Then: Report > Generate XML Report…
- Wapiti - .json or .xml results file.
Commercial (non-Free) DAST Tools:
- Acunetix Web Vulnerability Scanner (WVS) - .xml results file (see Exporting Scan Results (Generic XML export)) was the command line /ExportXML switch) or .xml results file from Acunetix 360
- Burp Suite Pro - .xml results file
- To generate XML results: click on benchmark in site map so you see ALL findings in Issues pane. Then select ALL issues in Issues pane, right-click and select ‘Report selected issues’. Select XML, then next, next, next, and save to file. To reduce size of results file, you can eliminate all the details, and not include requests/responses, which reduces the file size by 2/3rds.
- Fluid Attacks DAST - .csv results file
- HCL AppScan Standard - .xml results file
- Micro Focus Fortify WebInspect - .xml results file
- Netsparker - .xml results file
- Qualys Web App Scanner - .xml results file
- Rapid7 AppSpider - .xml results file
If you have access to other DAST Tools, PLEASE RUN THEM FOR US against the Benchmark, and send us the results file so we can build a scorecard generator for that tool.
Commercial Interactive Application Security Testing (IAST) Tools:
- Checkmarx CxIAST - .csv results file
- Contrast Assess - .log results file
- You can scan Benchmark w/Contrast Assess for free. See: https://www.contrastsecurity.com/contrast-community-edition
- Datadog Application Vulnerability Management - .log results file
- Synopsys Seeker IAST - .csv results file
Commercial Hybrid Analysis Application Security Testing Tools:
- Fusion Lite Insight - .xml results file
WARNING: If you generate results for a commercial tool, be careful who you distribute it to. Each tool has its own license defining when any results it produces can be released/made public. It may be against the terms of a commercial tool’s license to publicly release that tool’s score against an OWASP Benchmark. The OWASP Benchmark project takes no responsibility if someone else releases such results.
People frequently have difficulty scanning the OWASP Benchmark with various tools due to many reasons, including size of the Benchmark app and its codebase, and complexity of the tools used. Here is some guidance for some of the tools we have used to scan the Benchmark. If you’ve learned any tricks on how to get better or easier results for a particular tool against the Benchmark, let us know or update this page directly.
Generic Tips
Because of the size of the OWASP Benchmark, you may need to give your tool more memory before it starts the scan. If its a Java based tool, you may want to pass more memory to it like this:
-Xmx4G (This gives the Java application 4 Gig of memory)
SAST Tools
Checkmarx
The Checkmarx SAST Tool (CxSAST) is ready to scan the OWASP Benchmark out-of-the-box. Please notice that the OWASP Benchmark “hides” some vulnerabilities in dead code areas, for example:
if (0>1)
{
//vulnerable code
}
By default, CxSAST will find these vulnerabilities since Checkmarx believes that including dead code in the scan results is a SAST best practice.
Checkmarx’s experience shows that security experts expect to find these types of code vulnerabilities, and demand that their developers fix them. However, OWASP Benchmark considers the flagging of these vulnerabilities as False Positives, as a result lowering Checkmarx’s overall score.
Therefore, in order to receive an OWASP score untainted by dead code, re-configure CxSAST as follows:
- Open the CxAudit client for editing Java queries.
- Override the “Find_Dead_Code” query.
- Add the commented text of the original query to the new override query.
- Save the queries.
CodeQL
To use the CodeQL command line interface (CLI) on Benchmark, first install CodeQL and its rules databases per: https://codeql.github.com/docs/codeql-cli/using-the-codeql-cli/ (i.e., codeql and the codeql-repo).
Once this is done, do the following:
- Navigate to the OWASP Benchmark project directory
- ~/PATHTO/codeql/codeql database create owasp-benchmark –languages java
- ~/PATHTO/codeql/codeql database analyze owasp-benchmark java-security-and-quality.qls –format=sarifv2.1.0 –output=results/Benchmark-CodeQL.sarif
You can also try different CodeQL query suites other than: java-code-scanning.qls. To get a list, run: ~/PATHTO/codeql/codeql database analyze owasp-benchmark –format=sarifv2.1.0 –output=results/Benchmark-CodeQL.sarif. When you do, a usage message will be displayed. Something like: “No queries were specified … one of these query suites might be what you want?” And then a list is displayed. 5 different query suites starting with ‘java-‘ were listed when we ran it. We determined that only 2 query suites include their Weak Random rule (java-security-and-quality.qls and java-lgtm-full.qls).
Kiuwan Code Security
Kiuwan Code Security wrote their own instructions for scanning the OWASP Benchmark. Refer to their step-by-step guide on the Kiuwan website.
Micro Focus (Formerly HP) Fortify
If you are using the Audit Workbench, you can give it more memory and make sure you invoke it in 64-bit mode by doing this:
set AWB_VM_OPTS="-Xmx2G -XX:MaxPermSize=256m"
export AWB_VM_OPTS="-Xmx2G -XX:MaxPermSize=256m"
auditworkbench -64
We found it was easier to use the Maven support in Fortify to scan the Benchmark and to do it in 2 phases, translate, and then scan. We did something like this:
Translate Phase:
export JAVA_HOME=$(/usr/libexec/java_home)
export PATH=$PATH:/Applications/HP_Fortify/HP_Fortify_SCA_and_Apps_17.10/bin
export SCA_VM_OPTS="-Xmx2G -version 1.7"
mvn sca:clean
mvn sca:translate
Scan Phase:
export JAVA_HOME=$(/usr/libexec/java_home)
export PATH=$PATH:/Applications/HP_Fortify/HP_Fortify_SCA_and_Apps_4.10/bin
export SCA_VM_OPTS="-Xmx10G -version 1.7"
mvn sca:scan
PMD
We include this free tool with the Benchmark for Java and its all dialed in. Simply run the script: ./script/runPMD.(sh or bat). If you want to run a different version of PMD, just change its version number in the Benchmark pom.xml file. (NOTE: PMD doesn’t find any security issues. We include it because its interesting to know that it doesn’t.)
SpotBugs
We include this free tool with the Benchmark for Java and its all dialed in. Simply run the script: ./script/runSpotBugs.(sh or bat). If you want to run a different version of SpotBugs, just change its version number in the Benchmark pom.xml file.
SpotBugs with FindSecBugs
FindSecurityBugs is a great plugin for SpotBugs that significantly increases the ability for SpotBugs to find security issues. We include this free tool with the Benchmark and its all dialed in. Simply run the script: ./script/runFindSecBugs.(sh or bat). If you want to run a different version of FindSecBugs, just change the version number of the findsecbugs-plugin artifact in the Benchmark pom.xml file.
DAST Tools
Burp Pro
To scan, first crawl the entire Benchmark. To do a crawl, right click on Benchmark in the Site Map, select Scan–>Open scan launcher. Then click on Crawl and hit OK. Then save the project in case of a crash during the scan. Then select the /Benchmark URL and invoke: ‘Actively scan this branch’. Prior to all this, you might want to give Burp more RAM before you start it (e.g., launch it like so: java -Xmx2G -jar burpsuite_pro.jar).
ZAP
ZAP may require additional memory to be able to scan the Benchmark. To configure the amount of memory:
- Tools –> Options –> JVM: Recommend setting to: -Xmx2048m (or larger). (Then restart ZAP).
To run ZAP against Benchmark:
- Because Benchmark uses Cookies and Headers as sources of attack for many test cases: Tools –> Options –> Active Scan Input Vectors: Then check the HTTP Headers, All Requests, and Cookie Data checkboxes and hit OK
- Click on Show All Tabs button (if spider tab isn’t visible)
- Go to Spider tab (the black spider) and click on New Scan button
- Enter: https://localhost:8443/benchmark/ into the ‘Starting Point’ box and hit ‘Start Scan’
- Do this again. For some reason it takes 2 passes with the Spider before it stops finding more Benchmark endpoints.
- When Spider completes, click on ‘benchmark’ folder in Site Map, right click and select: ‘Attack –> Active Scan’
- It will take several hours, like 3+ to complete (it’s actually likely to simply freeze before completing the scan - see NOTE: below)
For faster active scan you can:
- Disable the ZAP DB log (in ZAP 2.5.0+):
- Disable it via Options / Database / Recover Log
- Set it on the command line using “-config database.recoverylog=false”
- Disable unnecessary plugins / Technologies: When you launch the Active Scan
- On the Policy tab, disable all plugins except: XSS (Reflected), Path Traversal, SQLi, OS Command Injection
- Go the Technology Tab, disable everything and only enable: MySQL, YOUR_OS, Tomcat
- Note: This 2nd performance improvement step is a bit like cheating as you wouldn’t do this for a normal site scan. You’d want to leave all this on in case these other plugins/technologies are helpful in finding more issues. So a fair performance comparison of ZAP to other tools would leave all this on.
To generate the ZAP XML results file so you can generate its scorecard:
- Tools > Options > Alerts - And set the Max alert instances to like 500.
- Then: Report > Generate XML Report… NOTE: Similar to Burp, we can’t simply run ZAP against the entire Benchmark in one shot. In our experience, it eventually freezes/stops scanning. We’ve had to run it against each test area one at a time. If you figure out how to get ZAP to scan all of Benchmark in one shot, let us know how you did it!
Things we tried that didn’t improve the score:
- AJAX Spider - the traditional spider appears to find all (or 99%) of the test cases so the AJAX Spider does not appear to be needed against Benchmark v1.2
- XSS (Persistent) - There are 3 of these plugins that run by default. There aren’t any stored XSS in Benchmark, so you can disable these plugins for a faster scan.
- DOM XSS Plugin - This is an optional plugin that didn’t seem to find any additional XSS issues. There aren’t an DOM specific XSS issues in Benchmark v1.2, so not surprising.
IAST Tools
Interactive Application Security Testing (IAST) tools work differently than scanners. IAST tools monitor an application as it runs to identify application vulnerabilities using context from inside the running application. Typically these tools run continuously, immediately notifying users of vulnerabilities, but you can also get a full report of an entire application. To do this, we simply run the Benchmark application with an IAST agent and use a crawler to hit all the pages.
Contrast Assess
To use Contrast Assess, we simply add the Java agent to the Benchmark environment and run the BenchmarkCrawler. The entire process should only take a few minutes. We provided a few scripts, which simply add the -javaagent:contrast.jar flag to the Benchmark launch configuration. We have tested on MacOS, Ubuntu, and Windows. Be sure your machine or VM has at least 4M of memory.
- Ensure your environment has Java, Maven, and git installed, then build the Benchmark project
$ git clone https://github.com/OWASP-Benchmark/BenchmarkJava.git $ cd Benchmark $ mvn compile - Download a copy of the Contrast Java Agent configuration file (contrast.yaml) from your Contrast TeamServer account and put it in the tools/Contrast directory.
$ mv ~/Downloads/contrast.yaml tools/Contrast - In Terminal 1, launch the Benchmark application and wait until it starts
$ cd tools/Contrast $ ./runBenchmark_wContrast.sh (.bat on Windows) [INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building OWASP Benchmark Project 1.2 [INFO] ------------------------------------------------------------------------ [INFO] ... [INFO]_[talledLocalContainer] Tomcat 8.x started on port [8443] [INFO] Press Ctrl-C to stop the container... - In Terminal 2, launch the crawler and wait a minute or two for the crawl to complete.
$ ./runCrawler.sh (.bat on Windows) - A Contrast report has been generated in ./tools/Contrast/working/contrast.log. This report will be automatically copied (and renamed with version number) to ./results directory.
$ more tools/Contrast/working/contrast.log 2016-04-22 12:29:29,716 [main b] INFO - Contrast Runtime Engine 2016-04-22 12:29:29,717 [main b] INFO - Copyright (C) 2019 2016-04-22 12:29:29,717 [main b] INFO - Pat. 8,458,789 B2 2016-04-22 12:29:29,717 [main b] INFO - Contrast Security, Inc. 2016-04-22 12:29:29,717 [main b] INFO - All Rights Reserved 2016-04-22 12:29:29,717 [main b] INFO - https://www.contrastsecurity.com/ ... - Press Ctrl-C to stop the Benchmark in Terminal 1. Note: on Windows, select “N” when asked Terminate batch job (Y/N))
[INFO]_[talledLocalContainer] Tomcat 8.x is stopped Copying Contrast report to results directory - In Terminal 2, generate scorecards in ./scorecard
$ ./createScorecards.sh (.bat on Windows) Analyzing results from Benchmark_1.2-Contrast.log Actual results file generated: /Users/owasp/Projects/BenchmarkJava/scorecard/Benchmark_v1.2_Scorecard_for_Contrast.csv Report written to: /Users/owasp/Projects/BenchmarkJava/scorecard/Benchmark_v1.2_Scorecard_for_Contrast.html - Open the Benchmark Scorecard in your browser
/Users/owasp/Projects/BenchmarkJava/scorecard/Benchmark_v1.2_Scorecard_for_Contrast.html

Project Information
- Lab Project
Classification
- Tool
Audience
- Builder
- Defender
Code Repository
Downloads
- Git clone URL for Benchmark for Java
- Git clone URL for Benchmark for Python
- Docker Image
- Git clone URL for Scoring Utils
Introductory Materials
Contacts
- Report an issue for Benchmark for Java
- Report an issue for Benchmark for Python
- Report an issue for Benchmark Utils
- Contributing
Licensing
Leaders
- Dave Wichers (Project Lead)