OWASP Jupiter
An Application Security program is more successful when coverage of its processes and tooling can be proven. Unfortunately, software inventory lists consist of some custom-written applications for an organization but also include systems and software that aren’t in scope for a traditional AppSec program (Active Directory or Adobe Reader, for instance).
Making matters worse, organizations are constantly transforming the ways they operate. New software is being written and deployed every day:
- Microservices
- Marketing sites
- Batch jobs
- New e-commerce features
- Mobile apps
Traditional ITAM solutions aren’t tracking these custom-written applications that are the lifeblood of your organization because they aren’t designed to find them.
If “who owns this?” or “did you know this was in production?” sounds familiar, you’re not alone.
Jupiter Application Inventory Management System

What if we leveraged those DevOps processes to gather crucial information about the organization’s software applications?
Defining Application
What is an application?
Asking that question to five different people will probably yield five different answers. In terms of what the Jupiter Application Inventory Management System considers an application, it can be thought of as a singular module or code project unit that is built and deployed independently (aside from data or operating environment dependencies).
Taking another step, an application has certain attributes. It has a name. It has a codebase and thus a code repository. Where is that repository? It might have a team that supports it and somebody who is ultimately responsible for it. Who owns it? These are the types of questions Jupiter helps to solve.
Data collected includes:
- Common Name: The most widely known or current name of the application
- Aliases: Other names the application might have or have had previously
- Description: A brief synopsis of the application’s purpose for existing
- Code Repository URL: The location where the application’s code is stored and versioned
- Binary Repository URL: The location where build artifacts are stored and versioned
- Primary Language: The most prominent programming language used in the application’s codebase
- Secondary Languages: Additional programming languages used in the application’s codebase
- Type: Applications might have a particular role inside of an application ecosystem, such as a microservice, user interface, batch job, etc.
- Primary Owner: A person who has ultimate responsibility for the direction or well-being of the application
- Secondary Owners: Other people who may be delegates of the Primary Owner
- Business Unit: Particularly important in large organizations, this is the specific group within the organization to which the application belongs
- Exposure: Applications have varying ways they can be exposed – internal to the organization, publicly available on the internet, or to a select group of users
- Number of Users: The number of users (or an estimate) of the application
- Data Classification: Many organizations have a data risk classification hierarchy and applications may fall into one of the categories
- Deployment Environment: Because the Collector captures information at the build and deployment stages, the specific environment to which the build is destined can be recorded (e.g. QA, UAT, Production, etc.)
- Deployment Environment URL: Correlating to the Deployment Environment, this is a URL for the application if it is a web application or service
- Risk Level: Many organizations have formal risk levels that determine prioritization of resources aside from data categorization (can be a factor of data classification and exposure)
- Regulations: Applicable regulations such as PCI, SOX, HIPPA, etc. can be listed
- Chat Channel: Many application development and support teams have a way to communicate with each other and to collaborate within their organization such as Slack or Glip
- Agile Scrum Board URL: Development teams often keep a list of their in-flight work and backlog in a project tracking system such as Jira or Redmine
- Build Server URL: The CI server from which the recorded build or deployment originated
- Age: Applications can have a long life and understanding a given application’s age can help determine risk and gauge other implications
- Lifecycle Stage: Similar to age, an application can be New, in a Maintenance steady-state, or in Retirement
- Last Deployment Date: The last date on which the application was deployed
High Level Design
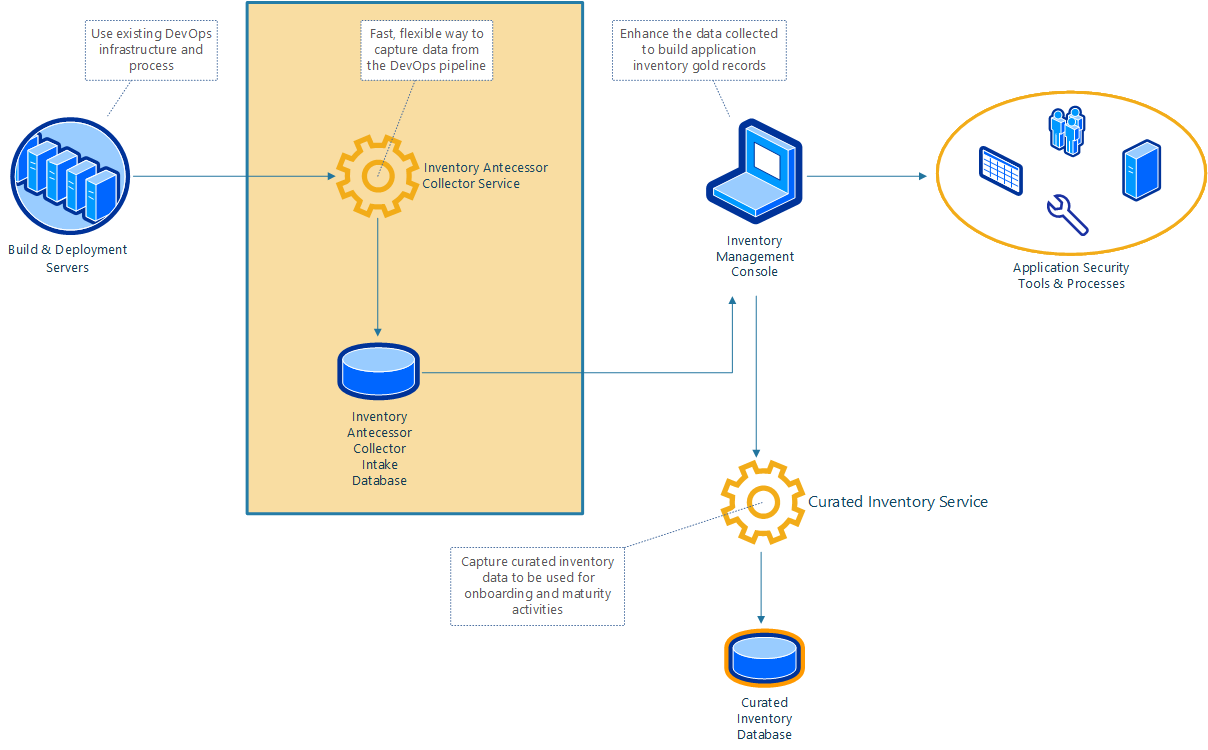
First, the Jupiter Collector Service can gather primitive inventory data (antecessors) directly from DevOps tools, such as continuous integration servers like Jenkins via the Jupiter Collector Plugin, when the software is built and deployed.
The Inventory Management Console connects to the collector service and facilitates enrichment of the antecessor data into “gold records” representing an application. These records are captured and stored directly by the Curated Inventory Service via REST API or through the Inventory Management Console.
Inventory Management Console
The Inventory Management Console is a graphical web interface that brings collection and curation of the inventory data together. This user-friendly application can then help with creating projects in application security tools, accelerating testing and assessment activities.
FAQ
Q: Why is this project named “Jupiter”?
A: In 2001: A Space Odyssey, the Discovery One embarked on a mission to investigate the signal sent from the monolith on the Moon to Jupiter. In 2010: The Year We Make Contact, the crews of the Discovery and Leonov witness countless monoliths emerge from Jupiter before it is converted into a star. Aside from the cool sci-fi reference, there is an analog to what this project is for – to start with a small amount of information about software applications in an organization’s portfolio and build upon that knowledge to find more.